Understanding ReLU - The Power of Non-Linearity in Neural Networks
Milind Soorya / January 02, 2024
3 min read

Why ReLU Introduces Non-Linearity
- Simplicity and Efficiency: ReLU has a very simple mathematical formula: f(x)=max(0,x)f(x)=max(0,x). This means that for any positive input, it just outputs the value, and for any negative input, it outputs zero. This simplicity leads to efficiency in computation, especially beneficial for deep neural networks with many layers.
- Handling Non-Linearity in Data: Real-world data is rarely linear. Think about speech patterns, image classifications, or financial markets; the relationships between inputs and outputs are complex and non-linear. ReLU helps neural networks capture this non-linearity, allowing the layers to learn from these complex patterns and make sophisticated predictions or classifications.
Why Non-Linearity is Important
- Beyond Linear Boundaries: If a neural network only performed linear transformations, no matter how many layers it had, it would still be equivalent to just one linear transformation. This severely limits the network’s capacity to understand and model the complexity found in real-world data. Non-linear activation functions like ReLU allow neural networks to learn and represent these complexities, breaking free from linear constraints.
- Deep Network Potential: Non-linearity allows for deep networks. With linear activation functions, adding more layers doesn’t increase the network’s capacity to learn more complex patterns. However, with non-linearity, each layer can transform the input in more complex and abstract ways, allowing deep networks to learn hierarchically and capture a wide variety of patterns in data.
- Sparse Activation: ReLU naturally leads to sparse activation. In a given layer, only a subset of neurons will activate (output a non-zero value). This sparsity makes the network more efficient and easier to train, as fewer neurons are firing, and thus, computations are reduced. It also helps in mitigating the issue of overfitting by providing a form of regularization.
Visualising
Try it out here — TensorFlow Playground
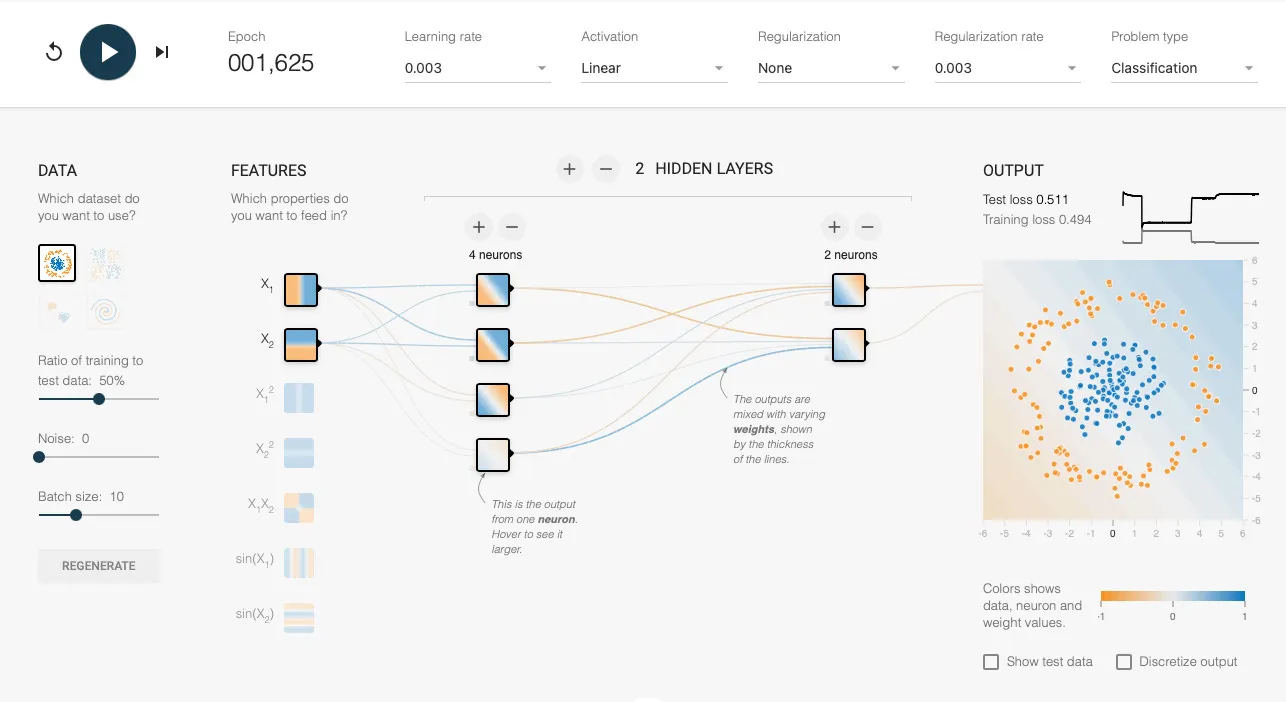
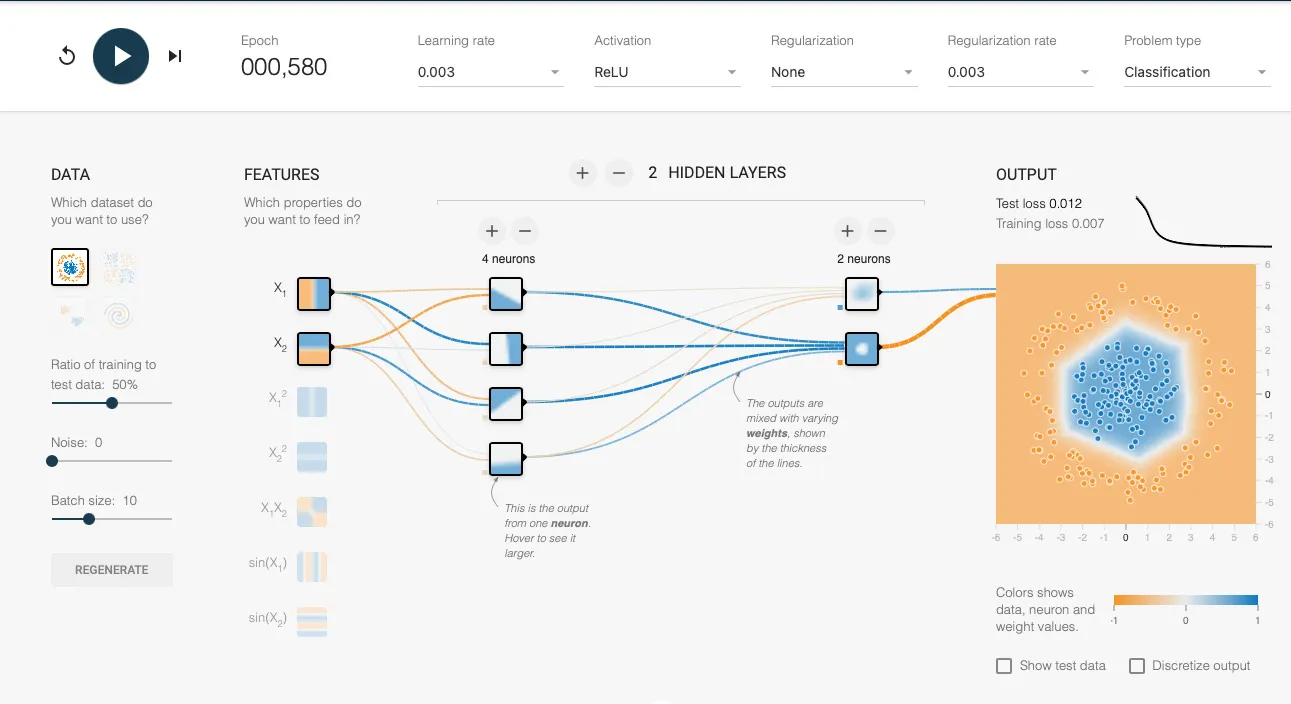
From the images provided, it’s evident that the data we aim to classify is spatially separated into two concentric circles. Using a linear function, we cannot accurately classify the blue and orange data points. However, when we employ ReLU activation, we achieve instant classification. It’s also worth noting that the boundary created using ReLU activation consists of straight lines.
Summary
In summary, ReLU introduces non-linearity to help neural networks better model the complex, non-linear relationships found in real-world data, enabling deep learning models to be more powerful, efficient, and capable of tackling a wide range of tasks from image recognition to natural language processing. Without non-linearity, neural networks would be far less effective, essentially reducing deep networks to simple linear regression models incapable of the sophisticated tasks they perform today.